2026
DepCache: A KV Cache Management Framework for GraphRAG with Dependency Attention
Hao Yuan, Xin Ai, Qiange Wang, Peizheng Li, Jiayang Yu, Chaoyi Chen, Xinbo Yang, Yanfeng Zhang, Zhenbo Fu, Yingyou Wen, Ge Yu
Special Interest Group on Management of Data (SIGMOD) 2026
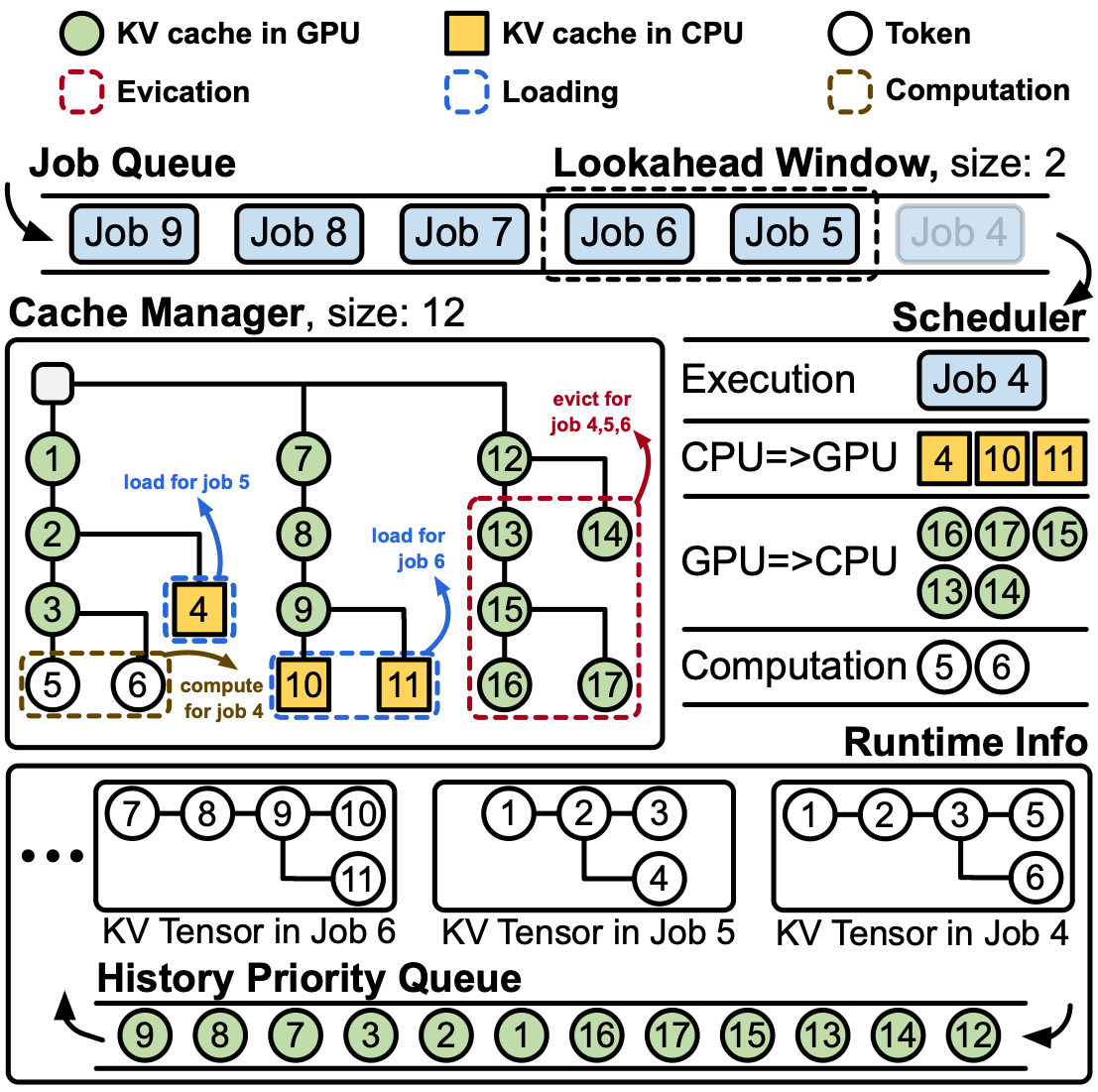
We introduce dependency attention, a novel graph-aware attention mechanism that restricts attention computation to token pairs with structural dependencies in the retrieved subgraph. Unlike standard self-attention that computes fully connected interactions, dependency attention prunes irrelevant token pairs and reuses computations along shared relational paths, substantially reducing inference overhead. Building on this idea, we develop DepCache, a KV cache management framework tailored for dependency attention.
DepCache: A KV Cache Management Framework for GraphRAG with Dependency Attention
Hao Yuan, Xin Ai, Qiange Wang, Peizheng Li, Jiayang Yu, Chaoyi Chen, Xinbo Yang, Yanfeng Zhang, Zhenbo Fu, Yingyou Wen, Ge Yu
Special Interest Group on Management of Data (SIGMOD) 2026
We introduce dependency attention, a novel graph-aware attention mechanism that restricts attention computation to token pairs with structural dependencies in the retrieved subgraph. Unlike standard self-attention that computes fully connected interactions, dependency attention prunes irrelevant token pairs and reuses computations along shared relational paths, substantially reducing inference overhead. Building on this idea, we develop DepCache, a KV cache management framework tailored for dependency attention.
NeutronHeter: Optimizing Distributed Graph Neural Network Training for Heterogeneous Clusters
Chunyu Cao, Xin Ai, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Hao Yuan, Mingyi Cao, Chaoyi Chen, Yingyou Wen, Yu Gu, Ge Yu
Proceedings of the International Conference on Management of Data (SIGMOD) 2026
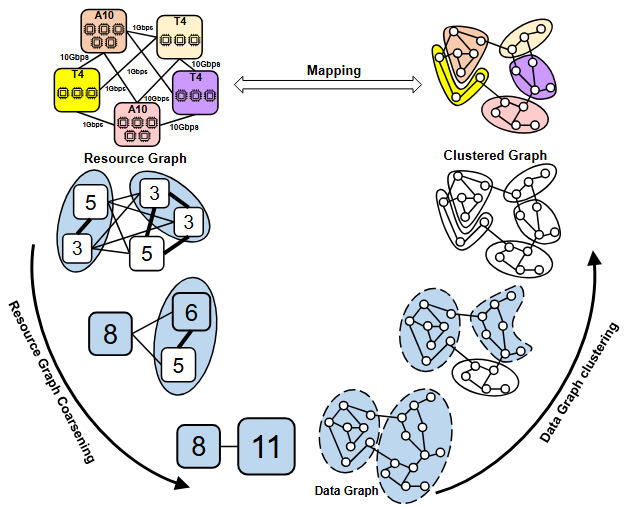
We present NeutronHeter, an efficient GNN training system for heterogeneous clusters. Our system leverages two key components to achieve its performance, including a multi-level workload mapping framework that transforms the complex multi-way mapping problem into a top-down workload mapping on a tree-like resource graph, and an adaptive communication migration strategy that reduces communication overhead by migrating communication from low-bandwidth links to local computation or high-bandwidth links.
NeutronHeter: Optimizing Distributed Graph Neural Network Training for Heterogeneous Clusters
Chunyu Cao, Xin Ai, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Hao Yuan, Mingyi Cao, Chaoyi Chen, Yingyou Wen, Yu Gu, Ge Yu
Proceedings of the International Conference on Management of Data (SIGMOD) 2026
We present NeutronHeter, an efficient GNN training system for heterogeneous clusters. Our system leverages two key components to achieve its performance, including a multi-level workload mapping framework that transforms the complex multi-way mapping problem into a top-down workload mapping on a tree-like resource graph, and an adaptive communication migration strategy that reduces communication overhead by migrating communication from low-bandwidth links to local computation or high-bandwidth links.
NeutronCloud: Resource-Aware Distributed GNN Training in Fluctuating Cloud Environments
Mingyi Cao, Chunyu Cao, Yanfeng Zhang, Zhenbo Fu, Xin Ai, Qiange Wang, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2026
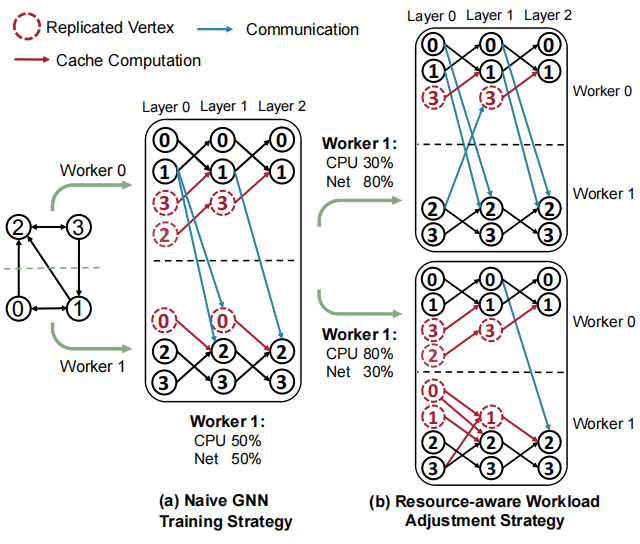
In this paper, we propose NeutronCloud, a system designed for efficient GNN training in cloud environments. First, we adopt a resource-aware workload adjustment strategy. It builds on hybrid dependency handling by obtaining dependency information through both local computation and remote communication. During training, it dynamically adjusts the ratio between locally computed and remotely fetched dependencies based on each worker's available resources, ensuring workload-resource alignment. Second, we employ a dependency-aware partial-reduce approach reusing historical vertex embeddings and skipping the stragglers during gradient aggregation to address extreme resource fluctuations that cause some workers to lag significantly behind others in the cluster.
NeutronCloud: Resource-Aware Distributed GNN Training in Fluctuating Cloud Environments
Mingyi Cao, Chunyu Cao, Yanfeng Zhang, Zhenbo Fu, Xin Ai, Qiange Wang, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2026
In this paper, we propose NeutronCloud, a system designed for efficient GNN training in cloud environments. First, we adopt a resource-aware workload adjustment strategy. It builds on hybrid dependency handling by obtaining dependency information through both local computation and remote communication. During training, it dynamically adjusts the ratio between locally computed and remotely fetched dependencies based on each worker's available resources, ensuring workload-resource alignment. Second, we employ a dependency-aware partial-reduce approach reusing historical vertex embeddings and skipping the stragglers during gradient aggregation to address extreme resource fluctuations that cause some workers to lag significantly behind others in the cluster.
2025
NeutronTP: Load-Balanced Distributed Full-Graph GNN Training with Tensor Parallelism
Xin Ai, Hao Yuan, Zeyu Ling, Xin Ai, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Chaoyi Chen, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2025
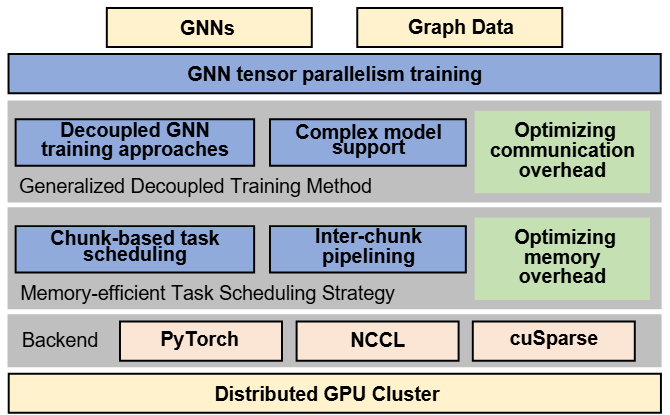
We present NeutronTP, a load-balanced and efficient distributed full-graph GNN training system. NeutronTP leverages GNN tensor parallelism for distributed training, which partitions feature rather than graph structures. Compared to GNN data parallelism, NeutronTP eliminates cross-worker vertex dependencies and achieves a balanced workload.
NeutronTP: Load-Balanced Distributed Full-Graph GNN Training with Tensor Parallelism
Xin Ai, Hao Yuan, Zeyu Ling, Xin Ai, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Chaoyi Chen, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2025
We present NeutronTP, a load-balanced and efficient distributed full-graph GNN training system. NeutronTP leverages GNN tensor parallelism for distributed training, which partitions feature rather than graph structures. Compared to GNN data parallelism, NeutronTP eliminates cross-worker vertex dependencies and achieves a balanced workload.
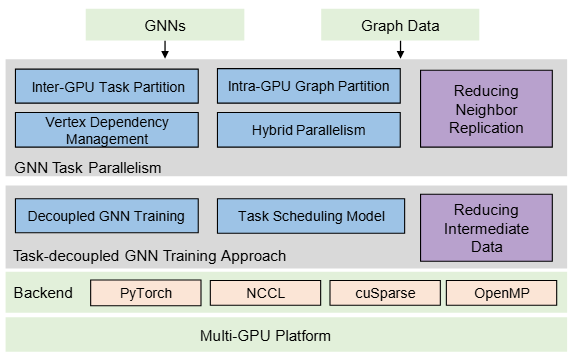
NeutronTask: Scalable and Efficient Multi-GPU GNN Training with Task Parallelism
Zhenbo Fu, Xin Ai, Qiange Wang, Yanfeng Zhang, Shizhan Lu, Chaoyi Chen, Chunyu Cao, Hao Yuan, Zhewei Wei, Yu Gu, Yingyou Wen, Ge Yu
Very Large Data Bases (VLDB) 2025
In this work, we propose NeutronTask, a multi-GPU GNN training system that adopts GNN task parallelism. Instead of partitioning the graph structure, NeutronTask partitions training tasks in each layer across different GPUs, which significantly reduces neighbor replication.
NeutronTask: Scalable and Efficient Multi-GPU GNN Training with Task Parallelism
Zhenbo Fu, Xin Ai, Qiange Wang, Yanfeng Zhang, Shizhan Lu, Chaoyi Chen, Chunyu Cao, Hao Yuan, Zhewei Wei, Yu Gu, Yingyou Wen, Ge Yu
Very Large Data Bases (VLDB) 2025
In this work, we propose NeutronTask, a multi-GPU GNN training system that adopts GNN task parallelism. Instead of partitioning the graph structure, NeutronTask partitions training tasks in each layer across different GPUs, which significantly reduces neighbor replication.
![NeutronRAG: Towards Understanding the Effectiveness of RAG from a Data Retrieval Perspective [Demo]](/assets/images/covers/sigmod-neutronrag.png)
NeutronRAG: Towards Understanding the Effectiveness of RAG from a Data Retrieval Perspective [Demo]
Peizheng Li, Chaoyi Chen, Hao Yuan, Zhenbo Fu, Xinbo Yang, Qiange Wang, Xin Ai, Yanfeng Zhang, Yingyou Wen, Ge Yu
Proceedings of the International Conference on Management of Data (SIGMOD) 2025
Existing RAG tools typically use a single retrieval method, lacking analytical capabilities and multi-strategy support. To address these challenges, we introduce NeutronRAG, a demonstration of understanding the effectiveness of RAG from a data retrieval perspective. NeutronRAG supports hybrid retrieval strategies and helps researchers iteratively refine RAG configuration to improve retrieval and generation quality through systematic analysis, visual feedback, and parameter adjustment advice.
NeutronRAG: Towards Understanding the Effectiveness of RAG from a Data Retrieval Perspective [Demo]
Peizheng Li, Chaoyi Chen, Hao Yuan, Zhenbo Fu, Xinbo Yang, Qiange Wang, Xin Ai, Yanfeng Zhang, Yingyou Wen, Ge Yu
Proceedings of the International Conference on Management of Data (SIGMOD) 2025
Existing RAG tools typically use a single retrieval method, lacking analytical capabilities and multi-strategy support. To address these challenges, we introduce NeutronRAG, a demonstration of understanding the effectiveness of RAG from a data retrieval perspective. NeutronRAG supports hybrid retrieval strategies and helps researchers iteratively refine RAG configuration to improve retrieval and generation quality through systematic analysis, visual feedback, and parameter adjustment advice.
2024
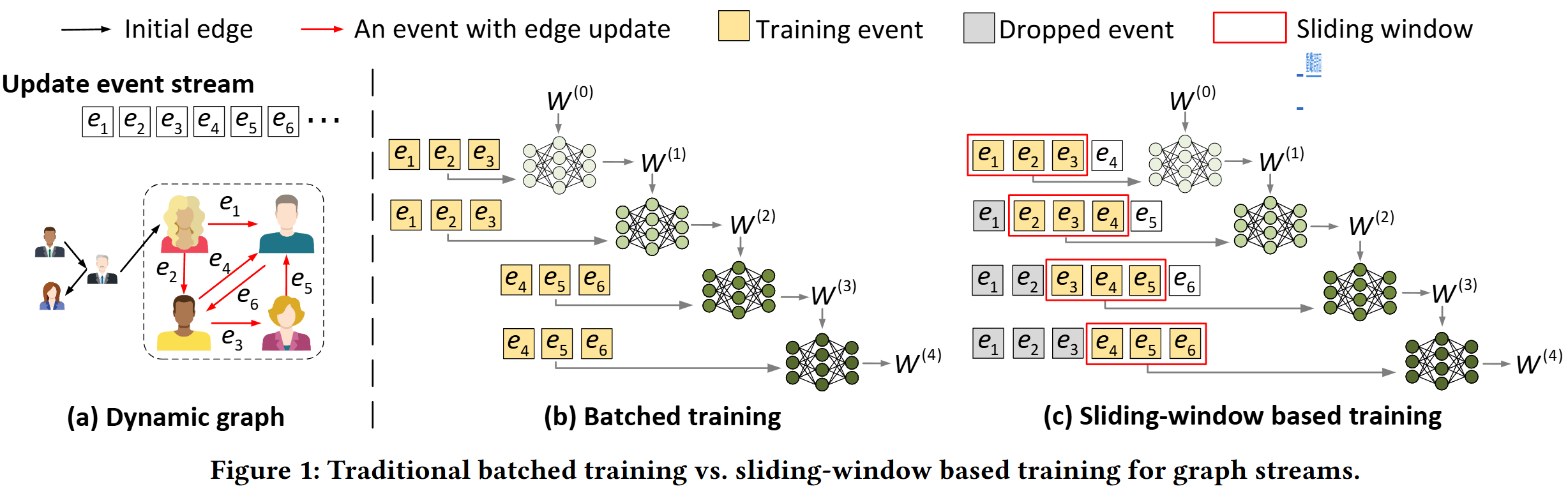
NeutronStream: A Dynamic GNN Training Framework with Sliding Window for Graph Streams
Chaoyi Chen, Dechao Gao, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Xuecang Zhang, Junhua Zhu, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2024
In this paper, we present NeutronStream, a framework for training dynamic GNN models. NeutronStream abstracts the input dynamic graph into a chronologically updated stream of events and processes the stream with an optimized sliding window to incrementally capture the spatial-temporal dependencies of events. Furthermore, NeutronStream provides a parallel execution engine to tackle the sequential event processing challenge to achieve high performance. NeutronStream also integrates a built-in graph storage structure that supports dynamic updates and provides a set of easy-to-use APIs that allow users to express their dynamic GNNs.
NeutronStream: A Dynamic GNN Training Framework with Sliding Window for Graph Streams
Chaoyi Chen, Dechao Gao, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Xuecang Zhang, Junhua Zhu, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2024
In this paper, we present NeutronStream, a framework for training dynamic GNN models. NeutronStream abstracts the input dynamic graph into a chronologically updated stream of events and processes the stream with an optimized sliding window to incrementally capture the spatial-temporal dependencies of events. Furthermore, NeutronStream provides a parallel execution engine to tackle the sequential event processing challenge to achieve high performance. NeutronStream also integrates a built-in graph storage structure that supports dynamic updates and provides a set of easy-to-use APIs that allow users to express their dynamic GNNs.